Comp 140 - Support Material
Course Links
Frequently Asked Questions
Microsoft Windows
- What are the various print screen keyboard shortcuts?
- Why does the Explorer not show my file extensions?
- Where do I get all the free Microsoft software for students?
Unix
- How do I protect my files on public_html from others?
- What Unix commands should I learn in this course?
Browser-related
Network-related
- How do I connect to my Camosun Computer Science network drive on my laptop?
- How do I get my e-mail from home?
- Can I do my labs at home?
- Can I forward my Camosun email to another email client?
Internet-related
- What is the internet?
- Who controls the internet?
- Could somebody buy the internet?
- What is net neutrality?
- I hear stories about the internet crashing. Is that going to happen?
- Why do I keep hearing news about security problems about the internet?
- What is an ISP?
- What is a browser?
- What is a web server?
- What is TCP/IP?
- What is an IP address?
- What is a protocol?
- What is an URL?
- What is a domain and subdomain?
- What are some examples of domains?
- How does a URL get mapped to an IP address?
- What is DNS?
- What is IP v6?
- What is HTTP?
- What is HTTPS?
- What is FTP?
- What is Telnet?
- What is SSH?
- What is a port?
- What is a MIME type?
- How does the browser know how to handle different types of files?
- What are absolute and relative URLs?
- What are the advantages and disadvantages of using absolute and relative URLs?
- What is the difference between the anchor references "../info/data.html", "./info/data.html", "/info/data.html, and "data.html"?
- What is the difference between a web server root, a server root, and a web site root?
- What does "load the HTML file locally" mean?
- Why do I have to set permissions on my files on m:\public_html?
- I typed in my HTML file but I still can't see anything in the browser.
- Can other people change my HTML files?
- What is a cookie?
- What is authentication?
- What do upload/download mean?
- What is the difference between intranet and internet?
- What is meant by "identity theft"?
- How do I protect my computer while surfing the net?
- What do phishing, spyware and spoofing mean?
- What is a trojan horse?
- What is cyber-squatting or domain-squatting?
- What is a search engine?
- What is search engine optimization?
- What is digital rights management?
- What was the first web page?
- What is DHCP?
- What is hotlinking?
- How much of the internet's web pages are compliant with W3C standards?
- What is googlewhacking?
HTML
- Why won't my HTML links work in the browser?
- What about frames?
- What does hypertext mean?
- What does hyperlink mean?
- Do I have to name my HTML files with a .htm or a .html?
- What does it mean when we say HTML files are text files?
- What does "white-space" mean?
- Will it make a difference in the browser if I add spaces and blank lines in my HTML file?
- What is an example of good HTML source code style?
- What is an example of bad HTML source code style?
- Are there other markup languages?
- What is XSLT?
- What are HTML entities?
- What is XHTML?
- What is a shtml file?
Flash
- How do I get motion tweening to work in Flash?
- Can I use Flash MX at home?
- How do I get sound into my Flash movie?
- How do I get a button into my Flash movie?
- How do I get my button to make a sound?
- How do I change how my button looks when I activate it?
- How do I get my button to do something useful?
- How did you construct that Comp 140 Flash?
DreamWeaver
- What do you mean by local folder?
- What do you mean by remote folder?
- How do I set up my site?
- How do I specify the FTP settings?
- Where is the imagemap panel?
Lab-related
Back to Top
Microsoft Windows
What are the various print screen keyboard shortcuts?
| alt-Print Screen | Capture the currently open window having focus |
| ctrl-Print Screen | Capture the entire screen (all open windows) |
| shift-Print Screen | Same as ctrl-Print Screen |
| ctrl-C | Copy selected item onto the clipboard |
| ctrl-Z | Cut selected item and place it onto the clipboard |
| ctrl-V | Paste selected item from the clipboard |
Why does the Explorer not show my file extensions?
The option to show the extension in the Explorer has been disabled. It is a good idea to see these file extensions because you may want to know if a file is named "abc.html" or "abc.htm". You can enable this option by following these two steps: 1. Open the File Explorer and select the Tools | Folder Options menu option. You may have to adjust the slider on the right down a bit until you see the File and Folder option for "Hide extensions for known file types". 2. Set this option off as show below.
Where do I get all the free Microsoft software for students?
Microsoft's MSDN Academic Alliance is a program that provides some Microsoft software (Microsoft Windows XP Professional, Microsoft Visual Studio .NET Professional, Microsoft Project Professional, Microsoft Visual Professional) to students and faculty for a very small cost (usually free or the cost of shipping the CDs to your address ~$15 US). Check https://msdn06.e-academy.com/elms/Security/Login.aspx?campus=camosun_cs - you will need a valid Camosun student email address to log on to the site to download the software. Check with your CST dept MSDNAA representative for details.
Back to Top
Unix
How do I protect my files on public_html from others?
Go to the write-up for a description.
What Unix commands should I learn in this course?
| ls | lists the contents of directories (called folders in Windows) |
| chmod | modifies the permissions of files and directories |
| cd | changes the working directory |
| rm | deletes files (use rmdir to delete directories) |
| cp | copies files |
| mkdir | creates a new directory |
| passwd | changes your deepblue account - note you will not get keyboard echo when you enter your password characters |
| logout | disconnect the session |
Details on these commands are in the Unix intro session.
Back to Top
Browser-related
How do you get the browser to do those window transitions?
Check out this resource on how it is done: http://pageresource.com/dhtml/jtut2.htm. The different transitions are sampled here.
What does cleaning out the cache mean?
In order to improve efficiency the browser maintains on your local profile a set of many files you have already downloaded from remote sites. These files include XHTML, JavaScript, Flash, and images. When you revisit sites with your browser, instead of downloading all that material again, the browser determines that the cache may contain those files and so speeds things up for you. Occasionally it may be necessary for you to "clean out the cache". This action means wiping out all the files stored in your local profile's cache so that when you revisit a web site, the browser is forced to download fresh files. If it appears that the browser is not picking up newer material that you have published on your web site, then it is a good idea to perform this activity. On the browser select Tools | Internet Options, then click "Delete Files" in the Temporary Internet files section as shown below.
Back to Top
Network-related
How do I get my e-mail from home?
Camosun no longer provides student email accounts. Students can use any other email provider service such as Google gmail, Microsoft hotmail, Yahoo, Shaw, Telus, or islandnet.Your Camosun e-mail is accessible via the browser using the Camosun weblink facility. Enter "https://www.cs.camosun.ca/webmail" as the URL in your browser, then enter your cst number followed by your password when prompted to login. An alternative is to enter https://hal.cs.camosun.ca/webmail as the URL. Note the "s" in the https.
You may opt to use the Pine e-mail
client
if you don't want any graphics. Pine is available from the
secure shell session.
How do I connect to my Camosun Computer Science network drive on my laptop?
For Windows XP operating systems you can either connect using the instructions in this PDF file or download the free version of SSH client here. Information on using SSH can be found here (PDF). You will need a student account and password to establish a connection.
WinSCP is better because it allows for editing your remote files but you will have to download the puTTY.exe terminal shell program separately, and then configure the WinSCP to use TextPad by default for editing your html files.The following instructions for connecting to the CST server from home will no longer work since VPN (Virtual Private Network) has been implemented.
- Start the File Explorer and select Tools, then Map Network Drive.
- Select any unused drive letter. In the folder box enter
\\204.174.60.19\user where user is your user id as in c0xxxxxx - Click OK.
- The password dialog box will appear, in the first box enter
computerscience\user where user is your user id as in c0xxxxx
and provide your password in the second box. Click OK to confirm. - Don't forget to disconnect the network connection when finished.
Using Windows 98 or earlier:
- This is not supported due to the difficulty in the configuration. Instead download any of the secure shell utilities (PuTTY, QVT) to establish secure communications to deepblue. Telnet requires you to interact with the server hal within a command line environment so you will have to brush up on your Unix commands. After you install the utility, run it, then select the "SSH" protocol and enter the host as "deepblue.cs.camosun.ca".
The Mac comes with its own client for establishing SFTP sessions and there are other Mac products that function similarly.
Can I do my labs at home?
Most of the labs of this course will require a connection to the CST asimov server. You can connect to it using the WinSCP or SSH application (downloadable here). Instructions for using SSH and instructions for using WinSCP.
You can use KompoZer, an open source web site package, to edit your web pages while you are working away from Camosun. In KompoZer you would need to set the publish settings similar to this screen and this one to work from home.
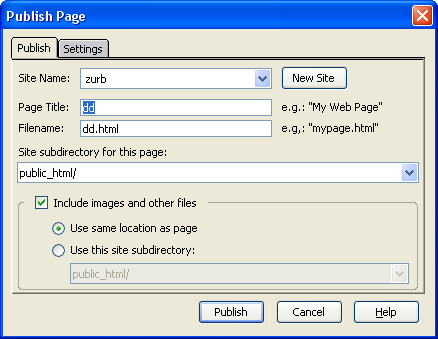{kind=link}
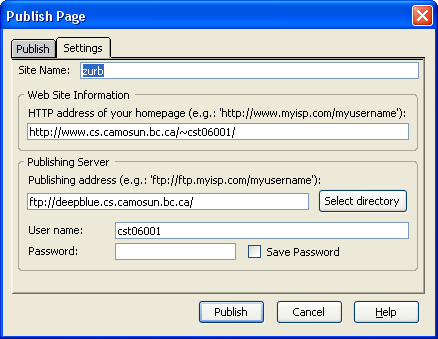{kind=link}
Can I forward my Camosun email to another email client?
No. This is currently not supported by Camosun.
Back to Top
Internet-related
What is the internet?
The Internet is a large global network comprised of millions of smaller networks. It is a world-wide instant broadcasting mechanism for dessiminating all kinds of information. The Internet is also a medium for collaboration and interaction between individuals without regard to geographic location. There are two parts to the Internet: information (content) and the network itself. The computers on the internet communicate with each other using a standard set of rules or "protocols".
Just after World War II scientists were finding ways to organize and share their accumulated wartime research. In 1945, scientist Vannevar Bush published his famous "As We May Think" essay in Atlantic Monthly. Bush proposed a large information indexing system that people all over the world could access and search. Even though his proposed system was never built, Bush's essay had a great influence on many who would one day design and build the Internet.
The beginning of the Internet starts in the US in 1962 as a series of memos by a researcher at MIT, J.C.R. Licklider, who envisioned a "Galactic Network" concept of globally interconnected computers. Licklider was the first head of computer research at a military advanced research projects agency called DARPA. While at DARPA Licklider convinced his successors of the importance of this networking idea. One successor and fellow researcher Lawrence Roberts published a plan in late 1966 for the "ARPANET" which served as a testbed for new networking technologies, linking universities and research centres.
The first node established on the ARPANET was the Network Measurement Center at UCLA in September 1969. The second was at the Stanford Research Institute. In October 1969 the first host-to-host message was sent from UCLA to Stanford via ARPANET. Two more nodes were added at UC Santa Barbara and University of Utah later that year. Computers were added quickly to the ARPANET during the following years and work continued on developing rules for network software.
A chief ARPANET architecht, Bob Kahn, organized a large, successful demonstation of the ARPANET In October 1972 at the International Computer Communication Conference. This was the first time the public could see this new technology. [1] [2]
The world's first web server was set up on a NeXT workstation by Tim Berners-Lee. The original computer is kept behind glass in Geneva, Switzerland.
Mapnet is a visualizing tool for viewing the global internet infrastructure.
How big is the internet? Click this chart and see. (Created by OnlineEducation.net).{kind=link}
Who controls the internet?
Nobody can control all aspects of the internet - it's too diverse, decentralized and just about pervasive now. The idea of the Internet was that of a distributed collection of networks which could withstand parts of it being disabled for whatever reason. If one part of the network went down, there would supposed to be another connection to the Internet around it.An internationally organized, non-profit corporation based in California called ICANN, Internet Corporation for Assigned Names and Numbers, is responsible for assigning top level domain names and allocating Internet Protocol (IP) address space. Through a public-private partnership ICANN accredits third-party domain registrars for various top-level domains (TLD). For example, all the .com domain registrations are managed by Verisign Global Registry Services.
Access to the internet is controlled mostly by internet service providers which include telephone companies, cable companies, and other third party companies which lease network access from those two.
Content on the internet is not generally subject to government or corporate censorship (exceptions include some countries, companies {2} and bulletin board portals). The exchange of ideas and differing viewpoints is what makes the Internet an engaging, progressive medium of communication; however, there are limits to what the public and legal institutions will tolerate as far as releasing objectionable, seditious or libelous material into the public domain.
Some content providers restrict their videos to within a geographic region, this is called geoblocking and is done by your current IP address lookup. For example, the Comedy Network US version ( http://www.comedycentral.com) domain access is forbidden to Canadians due to Canada's CTV network having made a business deal with Viacom over the distribution rights of content. The URL will send the browser to http://www.thecomedynetwork.ca instead.
In Canada there are many commercial internet service providers (Shaw, Bell, Telus, Rogers), some relatively small (IslandNet, PLNet) and not-for-profit (Victoria Free-Net). The ISPs are the transporters of internet content. Without them, you would not be able to access any internet resources. The responsibility of maintaining domain names within Canada (the dot ca Top Leave Domain) is the assigned to the non-profit Canadian corporation CIRA. Other companies in Canada will provide you with your own domain name registration for a fee but CIRA is the overseeing body for dot ca domain names.
Echelon is the code name for the NSA surveillance project to monitor all global communications.
Update Oct 1, 2009: ICANN has agreed to allow more global supervision of its top level domain names rather than exclusively American. [PDF]
Could somebody buy the internet?
No, the Internet is not a product or service you can purchase in its entirety. The Internet is not set up to be a commodity or a privately owned resource.
There are thousands of companies around the world making money selling products and services through the Internet. There are proprietary Internet locations called portals, for example, like AOL and Microsoft's MSN. As an AOL subscriber you would be given an account to connect to the internet and access AOL and other "premium" content.
Kevin Ham is a Vancouver-based dot-com mogul who currently owns the rights to several million domain names.
What is net neutrality?
Net neutrality means that the provider of internet services does not restrict which sites can be accessed or affect the speed of data download from certain web sites. The internet would not be as free, open and diverse if the providers of internet services allow access only to a select set of web sites. In Canada there is concern about metering access to the Internet. This is currently an ongoing issue in both the U.S. and Europe as there are parties interested in seeing access to some internet sites restricted from some users by ISPs, notably the American ISP Comcast. Without net neutrality in place access to internet web sites would possibly resemble this or this.
{kind=link}
{kind=link}
Ongoing update as of April 9, 2011 from the Boston Globe:
I hear stories about the internet crashing. Is that going to happen?
As the Internet's 30-year old technology has grown in popularity and demand by astronomical proportions, there are architecture limitations and security issues that are causing some concern. The volume of users on the Internet has increased tenfold in the last ten years and experts predict that growth will continue as new technology is fostered in developing countries. There have been pessimistic articles describing the Internet crashing under its own weight of daily traffic, graphics and sound. Back in 1996 due to human and technical problems AOL suffered a 19-hour outage for its (then) 6 million customers.
Despite these potential threats the Internet is not likely to experience a "crash". There is a great deal of redundancy and diversity in the network design that makes up the Internet.{kind=link}
An article (ZDNET, Oct 6,2005) about how an argument between two competing backbone ISPs (Level 3 Communications and Cogent Communications temporarily brought down the internet for some customers.
Why do I keep hearing news about security problems about the internet?
No, the Internet is not the 100% safe, secure and reliable facility for transmitting or receiving information.
Email spam now accounts for nearly 80% of all email traffic. There is heightened concern over viruses and worms causing loss or theft of information. Hackers write malicious program code which are hidden inside files and email messages designed to fool people into thinking they are genuine. When those files are opened or activated, the hidden code executes and can cause mayhem to the hapless client. Keylogging programs which monitor all your keystrokes can be unknowingly installed on the computer.
The best way to protect yourself is to install an antispam filter to your email client and an antivirus program (sometimes two different ones). Never open an email attachment which is a program or a non-text document unless you are absolutely sure about the sender. Use a PGP-based email authentication so that your email recipients are sure email actually came from you.A good article (Jan 11, 2007) about eliminating spam from your inbox.
Be especially vigilant surfing the Internet. Turn on pop-up blocking features and raise the security settings on the browser so that unsigned ActiveX controls will not be downloaded. A news article about authorities shutting down a 100,000 node zombie botnet. An internet security experts' consensus of the internet's top twenty security vulnerabilities. Not all are MS-Windows based.
What is an ISP?
The ISP, Internet Service Provider, is a company that supplies access to the Internet for home, office or institution. Many ISPs will allow customers to set up their own web site on the ISP web servers.
What is a browser?
The browser is the program on your computer that receives requested information from a web server and renders it appropriately in the browser window.Browsers rely on the Internet protocol HTTP to communicate information with web servers.
The first
browser was written in 1990 by Tim Berners-Lee photo,
a British
physics researcher working at CERN
in Switzerland at the time.
The first widely used web browser was NCSA
Mosaic developed in 1993 by then college student Marc
Andreessen. This early browser had a web interface that could
use Internet applications such as email, ftp, telnet and Gopher and
could display images, sound and video. In 1994 Andreessen
partnered with Silicon Graphics founder Jim Clark to create Mosaic
Communications. The Mosaic programming team then developed
the first commercial web browser called Netscape Navigator, later named
Communicator, then renamed to just Netscape. In 1999
Microsoft released Internet Explorer v3 bundled with its Windows
operating system and market share of Netscape browser fell
substantially. An open-source
version of Netscape was created called Mozilla,
and released in 2002. Market share for Mozilla recovered a
bit particularly on non-Windows platforms and in 2004, was released in
the popular FireFox version.
{kind=link}

The Opera
browser, developed by a team of Norwegian researchers, has also gained
in market share due to its speed, security and additional features such
as tabbed browsing.
Developed in 1993 by the University of Kansas, Lynx
is a browser for character-mode terminals without graphics capabilities.
If you want to see what it was like to use some of the early browsers,
visit dejavu.org.
As of May, 2005 Microsoft's Internet Explorer has a commanding market share in the world (89% in US, 70% in Germany, 90% in Japan). Firefox comes second at 7% in the US and 22% in Germany. Some other browser market share statistics and here too.
Features of a browser include
- cache, a location on the local computer for storing previously viewed web pages. This saves time and network bandwidth if the browser needs to show that page at some point again.
- plugins, a set of auxiliary programs designed to handle content such as video, audio or other applications
- history, a list of all your previously visited web pages, shown either in chronological or alphabetical order
- favorites (IE) or bookmarks (Netscape), a list of web pages you want to revisit
- security features to prohibit unauthorized activity on your computer if the visited web page attempts to do something you don't want it to
What is a web server?
Web servers are typically high end computers (lots of disk space, memory and processing power) which manage web sites. The server also refers to the software running on the computer that handles HTTP requests from clients for information from the web site.The most common web server is Apache, followed by Microsoft Internet Information Server (IIS).
What is TCP/IP?
An open suite of protocols used for Internet communications. TCP/IP has been called the "language of the Internet" as it allows many different kinds of computers, from personal computers to mainframes, to exchange information. The two main protocols in TCP/IP are TCP (Transmission Control Protocol) and IP (Internet Protocol). TCP permits communication between the various computers on the Internet, while IP specifies how data is routed from computer to computer. With TCP/IP, information is split into IP packets, and transmitted over the Internet. The advantages of this approach are:
- Error recovery - if a packet gets corrupted, only that small packet needs to be resent, not the entire message
- Load distribution - if one area of the network is congested, packets can be rerouted to less busy areas
- Flexibility - if the network experiences a failure or disruption in one location, packets can be rerouted.
Each packet of data also contains information about the computer that sent it, the computer it is being sent to, a sequence number indicating where the packet fits in the overall message, and error checking information to ensure that the packet is not corrupted during transmission. The packets are reassembled after being received at the destination computer. A message is sent from the destination computer to the sending computer to resend any missing or corrupted packets. This method, called packet switching, makes it easy to send data packets in any order, or even over a different network route. If packets arrive out of order, the sequence numbers are used to reconstruct the original message. [Fundamentals of the Internet and the World Wide Web, Greenlaw, Hepp]
For more information on TCP/IP see the Cisco reference.
What is an IP address?
Each computer on the Internet needs to be uniquely addressed so that routers can determine where to direct requests. The address is called an IP address. IP stands for Internet Protocol. The addresses are 32-bit numbers, expressed in a group of four numbers or "octets" as in
204.174.60.19
The term octet is used because the range of each number is in the range of 1 to 254. Zero and 255 cannot be used as IP addresses - those and some other numbers in the octet are reserved for other purposes. There are roughly 4.2 billion unique addresses using IP version 4.
Normally web servers have an
assigned IP address which will not change. That is a static
IP address. There is a mechanism for dynamically assigning a
new IP address to a computer when they need one. This frees
up a set of IP addresses that can be allocated on demand rather than
tying them all up when they aren't needed. So long as the
computer stays connected to the Internet with that IP address, they
keep that address. The next session could have a different IP
address.
On a Windows computer you can view your session Internet information by
enter the command IPCONFIG in the command window. On a Unix
computer, type nslookup machineName.
The IP version 4 address space allocation can be found here.
For example, IBM has reserved all IP v4 addresses that start
with 009.
Will the Internet run out of IP addresses? A 2002 report from
the European Commission says 74 percent of IP v4 addresses belong to
North American organizations, with the Massachusetts Institute of
Technology and Stanford each owning more addresses than the Peoples'
Republic of China.
The solution is to move on to the next generation of IP addressing schemes. No, that's not IP v5 but IP v6. The new version has a 128-bit address space and should deliver no fewer than 340 trillion trillion trillion possible addresses. That is estimated to be more than all the grains of sand on the world's beaches.
What happened to IP v5? It had already been allocated for another protocol in the late 1970's.
How do you find the geographic location of an IP address? You can find it at http://www.ip-adress.com (just one "d").
What is a protocol?
A protocol is a set of rules established by a group to promote a technology among vendors and suppliers. If all the different manufacturers of cell-phones used their own proprietary method for sending and receiving phone messages, there would be chaos and inefficiency. Since cell-phones in North America use CDMA technology or GSM (but not many), the market can focus on a standard used and supported by the industry. In the Internet world there are many protocols established to help computers "understand" each other. Some of these protocols include HTTP (Hypertext Transfer Protocol), SMTP (Simple Mail Transfer Protocol), FTP (File Transfer Protocol), telnet, Gopher, ARP (Address Resolution Protocol) and TCP/IP (Transmission Control Protocol/ Internet Protocol).
What is an URL?
The Universal Resource Locator provides information to the browser about the location of material you want to retrieve from the Internet. The URL defines how the material needs to be accessed (the protocol), where the material is found (web server) and what is the file name to be retrieved.
An example URL will look something like this:
http://www.cs.camosun.ca/~langs/comp140-12/index.html
The http defines the protocol or scheme used to talk to the web server. Other protocols include https, ftp, and gopher.
The www.cs.camosun.ca identifies the web server name (www) and domain name of the web server (cs.camosun.ca). Just about all web servers are assigned the name www as a convention but this is not a necessity for a URL.
The ~langs/comp140-12/index.html provides the local name to where the file is stored on the web server. If no name is specified, the web server where the page is located may supply a default file, which could be index.html or index.htm.
A URL may provide the IP address to the web server instead of the domain name as in http://204.174.60.19/~langs/comp140-07/index.html. The browser bypasses the request to the DNS for the IP address because the browser already knows it. The DNS makes it easy for us humans to remember web site addresses - it's easier to remember the URL cnn.com rather than its IP address equivalent.
A URL may also include a port number to the web server. This port number is 80 by default for web servers so it is omitted nearly all the time unless the URL needs to use a different port. The URL http://www.cs.camosun.ca:80/~langs/comp140-07/index.html includes its default port number so it isn't necessary to include it.
What is a domain and subdomain?
Think of all the computers connected to the Internet as leaves on a very big tree. Imagine the number of different branches the tree would have to accommodate the many leaves. This hierarchical concept is used to organize how all the Internet computers are addressed. There are a few main "branches" which branch off into sub-branches, and so on. The main branches of the Internet are called Generic Top-Level Domains (TLDs) and a few of them are shown below
| Generic Top Level Domain Name | Meaning |
| com | commercial business |
| edu | education |
| gov | U.S. government agency |
| mil | U.S. military |
| net | networking organization |
| org | nonprofit organization |
There are geographical Top-Level Domain names as well:
| Top Level Geographic Domain Name | Meaning |
| au | Australia |
| ca | Canada |
| de | Germany |
| uk | United Kingdom |
| za | South Africa |
The domains are further branched out into subdomains, each separated by a period as in cs.camosun.ca. The domain name system makes it easy to find where a computer is located on the Internet. Also, the responsibility for managing which devices are connected to the subdomains is distributed out. Each of .CA domain, .BC.CA subdomain, and the CAMOSUN.CA subdomain has a single governing body which manages which devices are connected to the subdomain.
New Top-Level Domains have been issued:
| biz | business organizations | http://www.neustarregistry.biz/ |
| info | organizations | http://www.nic.info/ |
| name | personalized domain | http://www.verisign.com/domain-name-services/domain-name-registries/name-domain-names/index.html |
| museum | international museums | http://www.nic.museum/ |
| coop | national cooperative business | http://www.nic.coop/ |
| aero | aerospace industry | http://www.nic.aero/gateway/index_html |
| tel | worldwide telephone directory | http://www.telnic.co.uk/ |
The management of Internet domain names and the DNS is handled by InterNIC (Internet Network Information Center), a subsidiary of the non-profit organization ICANN, Internet Corporation for Assigned Names and Numbers. The domain registrar for Canada is CIRA (Canadian Internet Registration Authority). From the 80's to the late 90's all internet domain names were centrally managed via a single organization, Network Solutions, operating under an agreement with the US National Science Foundation (NSF). In order to foster competition it was decided to privatize this process in 1998 and allow ICANN-accredited internet service providers to register domain names.
What are some examples of domains?
From IANI all the geographic domain codes. All top level domain list.If your company needs to register a domain name for your web
site, you can verify your desired name is
still available through a number of web sites like register.com and
sibername.com. Occasionally a company may not notice that
placing two seemingly innocuous English words
together as the domain name may cause ambiguity in the meaning. For
example, the IT technical support
website www.experts-exchange.com
used to be www.expertsexchange.com. A list of
some not so smart choices for domain names.
The news
item about a British gambling company paying $1.4 million to
acquire the domain vip.com.
How does a URL get mapped to an IP address?
Suppose you enter a URL of http://www.cs.camosun.ca/~langs/funstuff.html in the browser's address bar. How does the browser find out where to look?
- The URL's protocol is http which tells the browser what method to use to talk to the web server.
- The web server is www.cs.camosun.ca so the browser queries the DNS for the IP address.
- The DNS will respond with 204.174.60.19
- The browser next makes a TCP connection to 204.174.60.19. The default port for web servers is port 80.
- The browser then sends a message asking for the ~langs/funstuff.html file on the server
- The server responds to this request and send back the file funstuff.html found in the folder public_html for the account langs
- The TCP connection is closed. The "conversation" between the client and server has ended.
- The browser interprets the HTML information in funstuff.html and renders it in the display window
- The browser repeats these steps to retrieve any images contained within funstuff.html
What is DNS?
The Domain Name System (abbreviated DNS) is an Internet directory service. DNS is how domain names are translated into IP addresses, and DNS also controls email delivery. If your computer cannot access DNS, your web browser will not be able to find web sites, and you will not be able to receive or send email.
The DNS system consists of three components: DNS data (called resource records), servers (called name servers), and Internet protocols for fetching data from the servers.
There are thousands of DNS systems on the Internet performing translations of domain names into IP addresses every second.
If your DNS connection becomes unavailable, you won't be able to use domain names in your URLs in the browser - you would have to resort to supplying the servers' IP addresses instead.
An Internet utility called PING (Packet Internet Groper) can be used to find the IP address of a server. PING is also used to confirm that the host is "alive" and able to receive requests for information. Start a command shell in Windows and enter PING servername as in PING www.cs.camosun.ca.
What is IP v6?
When IP v4 was originally developed in the 1970s, it was thought 4.2 billion unique Internet addresses would be more than enough. But with the increase in the next generation and wireless technologies in the coming decade means that unique IP v4 addresses will all be claimed sooner than expected. China has been allotted only 20 million unique IP v4 addresses and many other Asian countries have much less. The next generation IP is IP v6 and it could provide each human being on the planet with millions of unique IP v6 addresses.
The new features of IP v6 include enhanced routing, security and support for wireless devices.
What is HTTP?
Web browsers and web servers communicate with each other using a set of rules called HTTP (hypertext transfer protocol). The HTTP "language" is actually simple and not difficult to read by humans. For example, a browser will send this HTTP message to a web server to request the web server's home page:
GET ? HTTP/1.0
Host: www.mysite.com
This message indicates that the browser wants to retrieve the
home page of the site mysite.com.
The web server will reply back to the browser:
HTTP/1.0 200 OK
Content-Type: text/html
<head>
<title>Welcome to mySite.com</title>
</head>
<body>
This is the main page for mySite.com
</body>
</html>
This message from the web server indicates that the server is also
speaking HTTP v1.0 protocol and that the request was successful.
If the requested page did not exist, the response would have
read "HTTP/1.0
404 Not Found".
The second line of the web server's reply indicates the kind of
information it is sending (HTML). This tells the browser how
to interpret the information from the server (render the HTML).
If a picture were being requested, then the Content-Type
could be "Content-Type:
image/png".
The standards
for using HTTP were created by the IETF
(Internet Engineering Task Force).
What is HTTPS?
HTTPS, an Internet protocol developed by Netscape, stands for Hypertext Transfer Protocol over Secure Socket Layer, or HTTP over SSL.
Sometimes information should be encrypted before it is transmitted between the browser and the web server. HTTPS encrypts and decrypts the page information using a secure Socket Layer. By default, HTTPS uses port 443 instead of the web server's port 80 for HTTP.
SSL uses a system that uses two keys to encrypt data - a public key known to all and a private own known only to the recipient of the message.
All major browsers support the HTTPS protocol and many web sites use the protocol to confirm confidential user information, such as credit card numbers. URLs that require an SSL connection will start with https: instead of http:.
Another secure version of HTTP is called S-HTTP but it has a different structure than HTTPS. Where SSL is designed to establish a secure connection between two computers, S-HTTP is designed to send individual messages securely.
What is FTP?
FTP (File Transfer Protocol) is an early Internet protocol used to transfer files between computers.
All major browsers support the FTP protocol. The URL for an FTP connection will start with the protocol ftp as in ftp://www.camosun.ca.
While
tranferring data over the network using FTP, there are
two modes: ASCII mode and binary mode. The difference is
crucial because if you transmit using binary mode, the receiving
computer will not examine the incoming bits to ensure there
are in the proper "format" for this computer. For example,
a Mac computer and a Unix computer store information in
different bit format.
There are disadvantages to using FTP, chiefly that the passwords and
file contents are sent unencrypted, which in theory could be
intercepted by someone.
There are
many free FTP client programs you can download which
will allow to copy files between your local computer and a remotely
connected computer.
There is a secure version of FTP called FTPS which uses the SSL to
encrypt the control and data transmission.
What is Telnet?
Telnet is another early (1969) Internet protocol based on TCP and is short for "telephone network". Telnet is intended to provide a login session directly to a remote computer. In a Telnet session you enter commands at a command line prompt to control some activity on the remote computer.
Telnet is a bad choice for many reasons from the point of view of computer security. Telnet by default does not encrypt any data sent over the connection (including passwords).
In 1995 a more secure and reliable protocol called SSH was released to replace Telnet.
What is SSH?
Developed by Tatu Ylönen in July 1995, a researcher in Finland, SSH was intended to be a secure open source protocol for performing file transfers or remote terminal sessions. There are many SSH clients you can download to use at home. PuTTY is one; SSH Tectia is another that we use in the CST department. You may download a copy of the SSH client from here.
What is a port?
A port on a server is a channel through which a communication connection has been established. There are 65535 ports - most are reserved by IANI for protocol transmissions and third party use. For example, Oracle uses port 66 for its SQL*NET communication.
What is a MIME type?
A MIME (Multi-purpose
Internet Mail Extensions) type
is a description of the kind of information transmitted from the web
server to the browser. In that respect a MIME type is similar
to a "file extension". A MIME type will have two parts: a
type and a subtype separated by a forward slash. For example,
the MIME type for Microsoft Word is application and the subtype is
msword. The complete MIME type is application/msword.
The
most commonly used MIME type for web page HTML
content is text/html.
Images will use a MIME type of image/png or image/jpeg.
A list of MIME types can be found at IANI.
How does the browser know how to handle different types of files?
The browser makes an HTTP request to the web server for a file. The web server locates the file and transmits the contents of the file back to the browser with some HTTP header information. The HTTP header contains a MIME type which informs the browser which type of file (HTML, text, video, audio) is being sent. The browser then determines what to do with the file: display it in the window (HTML), load a media player (audio), and so on. Programs are sent by the server with the MIME type of application/octet-stream. The browser may treat this information as something you want to download and prompt you to confirm.
What are absolute and relative URLs?
These are used in the HTML anchor tag's HREF attribute to define a hyperlink. An absolute URL is the fully qualified version that includes the protocol, server and file information as in http://www.cs.camosun.ca/~langs/comp140-12/labs/index.html A relative URL does not include the protocol or the server information ../labs/index.htmlBefore the browser can use a relative URL, it must resolve the relative URL to produce an absolute URL. If the relative URL begins with a double slash as in //www.cs.camosun.ca/~langs/comp140-12/), then it will inherit only the base URL's scheme. If the relative URL begins with a single slash as in /notes/html/), then it will inherit the base URL's scheme and network location. If the relative URL does not begin with a slash (e.g., index.html , ./index.html or ../notes/), then it has a relative path and is resolved as follows.
- The browser strips everything after the last slash in the base document's URL and appends the relative URL to the result.
- Each "." segment is deleted (e.g., ./index.html is the same as index.html, and ./ refers to the current "directory" level in the URL hierarchy).
- Each ".." segment moves up one level in the URL hierarchy; the ".." segment is removed, along with the segment that precedes it (e.g., notes/../index.html is the same as index.html, and ../ refers to the parent "directory" level in the URL hierarchy).
| quiz.html | refers to <URL:http://www.mysite.com/notes/html/quiz.html> (quiz.html needs to be in the same folder as index.html) |
| ./quiz.html | refers to <URL:http://www.mysite.com/notes/html/quiz.html> (quiz.html needs to be in the same folder as index.html) |
| ./ | refers to <URL:http://www.mysite.com/notes/html/> (same folder as /notes/html) |
| ../ | refers to <URL:http://www.mysite.com/notes> (one folder level higher than /notes/html) |
| ../tests.html | refers to <URL:http://www.mysite.com/notes/tests.html> (one folder level higher than /notes/html) |
| ../../labs/ | refers to <URL:http:/www.mysite.com/labs/> (two folder levels higher than /notes/html) |
What are the advantages and disadvantages of using absolute and relative URLs?
| advantage | disadvantage | |
| absolute URL |
|
|
| relative URL |
|
|
What is the difference between the anchor references "../info/data.html", "./info/data.html", "/info/data.html, and "data.html"?
The ".." always refers to one folder higher than the one you are at. The "." always refers to the current folder. The "/" in front always refers to the root folder of the web server. Assume we start with index.html in the work folder. So the reference ../info/data.html means look one folder higher (if you can) and go into the folder named info to get the file data.html.
The reference ./info/data.html means look in the current folder for the folder named info and get the file data.html. The reference /info/data.html means go to the web server root to find the folder named info and get the file data.html. This will not work. The reference data.html means get the file data.html from the current folder (same as ./data.html).
What is the difference between a web server root, a server root, and a web site root?
The web server root is the folder that is the base for storing all web site content. For Apache web servers, this folder is named htdocs by default. No internet access is allowed above this folder. The server root is the base folder for the entire server's operating system. For Unix computers, this is simply the / folder. No internet access is allowed at this level. The web site root is the base folder for a particular web site. For students' web sites at CST, this is your ~c0xxxxxx/public_html folder. No internet access is allowed above this folder.What does "load the HTML file locally" mean?
There is a URL scheme called file:// which is used when you want the browser to load in a file stored on the local computer. This completely bypasses the web server so the browser content may not work as expected. Be careful as you define your HREF attributes that this file:// scheme does not get entered. The web server will not understand it as it cannot access your local computer content.Why do I have to set permissions on my files and folders stored on public_html?
The following applies only if deepblue is used as the student web server. As of September 2007 asimov is the student web server and it runs Windows not Linux.If you are working in the CST labs and using TextPad to create new HTML files and saving them to your public_html folder, you will need to switch "on" the read permission to "other" to make those files accessible to the web server. That process can be easily done using SSH. If you are working in the CST labs and using TextPad to create new HTML files and saving them anywhere BUT public_html, you can use SSH file transfer to copy the files to your deepblue public_html folder and not have to set the read permission. The SSH file transfer will do that for you. Same thing if you are working at home - use SSH to transfer the files to public_html. Any folders you create on your public_html folder will require the execute permission for "other".
I typed in my HTML file but I still can't see anything in the browser.
Check the following:- Make sure the file is saved in your deepblue public_html folder.
- Make sure the file name you entered as the URL matches the file name in your public_html folder. Case matters!
- Make sure the file has the read permission for "other" switch on.
- Recheck your URL - it should start in the form of http://www.cs.camosun.ca/~your_deepblue_account
- Check that you can access other Internet content to confirm your connection is ok.
- Try a different browser.
Can other people change my HTML files?
No. They may be able to view the HTML source by clicking on View, then selecting Source but they won't be able to make any changes to the file or your public_html folder.What is a cookie?
Cookies are used by web sites to keep track of any information you may provide to them such as a user ID you would use to login to that web site. The cookies are small (4k) files stored locally on your computer and kept secure. They are not programs or anything that can be executed; they are simply text files. Cookie information is sent in the HTTP header between the browser and the server. You can disable the transmission of cookies in the browser and you may delete all the cookies stored on your computer if you wish.What is authentication?
Security implies that the right people have the right access to the right resources. In order to fulfill this, there needs to be a mechanism to validate the person requesting access to a resource. Authentication provides a means so that individuals can provide some kind of proof of who they are. This can be achieved with passwords or a biometric (fingerprint, iris scan, voice, or face scan).In September 2004, AOL announced that access to accounts would be made more secure through the optional premium of using RSA fobs, which are tiny devices that display random 6 digits every minute. When you sign on to AOL, you need to enter the fob's current 6 digit code. The random numbers are in sync with the main AOL servers, so if you don't have the right fob, the logon won't work.
What do upload/download mean?
Upload is the process of copying a file from the local computer to the remote computer ("up" through the pipe through the Internet "cloud"). Download is the process of copying a file from the remote computer to your local computer. FTP and SSH (or variations of them) are the most commonly used Internet facilities for uploading and downloading.What is the difference between intranet and internet?
If a company wants to provide online information to all its employees but restrict access to only employees, the company can create an "intranet". Similar in structure and design to the Internet (uses TCP/IP) but essentially private and much smaller in scope, intranets are a fast growing segment of the networking community. Employees would need to "sign in" to the company's main intranet site and then gain access to any intranet content. A firewall is used to ensure no unauthorized access is permitted from outside the intranet.What is meant by "identity theft"?
Identity theft is one of the fastest growing problems in the computer industry. Discarded bank receipts and credit card statements can be secretly collected and used to build up a new identity based on yours. There are malicious web sites purporting to be authentic commerce businesses that prompt you for your personal financial information. Once these sites have your bank ID number and password, that information could used or sold off.How do I protect my computer while surfing the net?
Web site hackers have targeted the Microsoft Internet Explorer and other browsers' security vulnerabilities. The user surfs to a malicious web site and if JavaScript is enabled in the browser, the web site's JavaScript exploits the vulnerability. In some cases a new program can be downloaded, installed and activated on the user's computer without knowing. Instructions for disabling Javascript in the browser can be found here. A company called Netcraft has developed a browser toolbar that will trap phishing web sites.Microsoft recommends setting the browser security to High, disable pop-ups, open email attachments ONLY if they are text, and add sites you consider safe to your list of trusted sites. Additional information for kids. Also, Secunia security postings for browsers and US CERT(Computer Emergency Readiness Team) advisories.
What do phishing, spoofing, and spyware mean?
Phishing is fooling people into providing their private information such as credit card numbers, bank IDs, passwords, and so on. After the Katrinia hurricane, a number of phishing web sites appeared asking for charitable donations to help the hurricane victims. Emails containing links to the phishing web sites were sent out. There are reports that hackers are mimicking the HTML of web sites of banks and other financial institutions in order to scam unwitting victims into supplying ids and passwords. Phishing is an authentication security vulnerability. How do you confirm that the person on the other side of the transaction is who they are? The best defence is knowledge and vigilance. Banks (or other companies for that matter) will never send you an email about unusual activity on your account and ask you to click on a link in the email. If an actual bank does that to you, switch banks as soon as possible - they obviously don't know about email authentication vulnerabilties. Spoofing is exploiting the fact that Internet email is inherently unsecure. Unless you are using PGP, you cannot guarantee email you receive is in fact from the person listed on the email's from: header. It is a trivial matter to build an automated program that can generate emails having any email in the header's "from:". Other email header information will show where the email orgiinally came from but that data is not usually shown. DNS can be spoofed as well. Spyware are programs designed to capture your personal information as you surf the net or capture your keystrokes - especially malicious if you are typing in your bank ID and password into your financial institution web site. The spyware gathers the information behind the scenes, then packages it off through the internet to the recipient without your knowing. Spyware doesn't replicate itself to other computers as viruses and worms do. Browser hijackers are mostly Javascript programs that cause your browser to load up the wrong web site. Your home page could be changed or your default search engine could be redirected. Say you enter a URL of www.mybank.com into the browser address bar while the browser hijacker is running, the hijacker intercepts that address request and sends a request to a different server called www.mybank.money.com. That site will have been made to look identical to www.mybank.com but it is not the same domain and you could be fooled.What is a trojan horse?
A trojan horse is a malicious program disguised as something useful or beneficial. A web site may offer a new Windows accelerator utilty you can download, but contained inside that program you just installed is something else that monitors your web activity. Bonzi Buddy is a good example of a trojan horse. Targeted at kids surfing the net the Bonzi Buddy talking purple ape was used as an enducement but the software agent behind the scenes installed spyware.What is cyber-squatting or domain-squatting?
The practice of acquiring the rights to an Internet domain name that arguably, one doesn't have legal claim. For example, an attempt by myself to register the domain name to a celebrity (the WIPO results), a well-known brand or large corporation would qualify as cybersquatting. Those that do this often post derogatory remarks on that web site or hope to resell their domain.Domain name disputes are typically resolved using the Uniform Domain Name Resolution Policy (UDRP) process developed by the Internet Corporation for Assigned Names and Numbers (ICANN).
Results of the dispute involving the Alberta Motor Assocation.
What is a search engine?
A search engine is a program that looks for a word or words contained in web pages. Google is a search engine which performs a massive indexing of as many web pages on the Internet it can see. The indexing of the terms makes the search process very fast. Search engines can be customized to search only within a web site as well. Search engines employ robot programs called crawlers or spiders which go out to all the web sites' pages and look at the HTML <meta> tags to collect keywords used on the page. Nielson's search engine ratings.What is search engine optimization?
In business you want your brand to be the most prominent, most recognized. A potential customer enters the term "widget" in the search engine, you want your brand of "widget" to appear at the top of the retrieved search entries. Forty percent of people who do online searches do not look past the first page of retrieved entries.Search engines have a proprietary system to rank their retrievals but web designers can assist search engines by using the HTML <meta> tag on their HTML pages. This tag lists the keywords the search engine can use to help index the page. Another factor is the frequency of those keywords appearing on that web page. Web pages that contain a number of links to other sites and if that page appears as a link on other sites affects the search score. A summary for improving search engine retrievals shows these and other useful techniques.
In addition companies can purchase the right to appear in a separate "paid" ranking.
What is digital rights management?
In the digital age where pictures, music, games, programs and movies are easily accessible through the internet, the issue of controlling and restricting the use of these products has become important. There are technologies that are intended to prevent the illegal copying and downloading of artists' works but there are advocates who argue that this approach could stifle innovation and lead to the loss of the products' use.All DRM technologies are designed to protect the copyright holder but still enable fair use by the consumer. To date all DRM schemes can be circumvented through organized, unlicensed piracy.
What was the first web page?
According to the person who would know, Tim Berners-Lee, it is http://nxoc1.cern.ch/hypertext/WWW/TheProject.html from late 1990. That page is no longer served by a later copy from 1992 exists at http://www.w3.org/History/19921103-hypertext/hypertext/WWW/TheProject.html From http://www.w3.org/People/Berners-Lee/FAQ.html#Examples.What is DHCP?
The acronym DHCP stands for Dynamic Host Configuration Protocol and is used to manage the allocation of IP addresses and other internet configuration information within a network. Typically a DHCP server maintains a 'pool' of available IP addresses and hands them out to client computers when they need to establish an internet connection. The 'dynamic' part refers to the client computer being able to 'lease' an available IP address for a period of time ranging from hours to months. Description of the DHCP standard from the IETF.Other handy TCP/IP applications are: PING (Packet Internet Groper) for determining if a host is reachable/alive, WHOIS for determining who owns a domain name, an IP address on the internet; TRACEROUTE uses ping to follow a path from internet hosts to get to the destination host.
A sample network tool page which demonstrates these utilities: http://www.iservetech.com/network-tools/nqt.phpWhat is hotlinking?
Hotlinking refers to the use of including an image (or other type of content) from a different web site within one of your web page as an HTML link. For example, a web page that describes varieties of apple trees includes images which are stored on a server controlled by some other person or group. For commercial web sites the issue of hotlinking can result in copyright law violation if web site A's images are being hotlinked by web site B which has not received permission to do so from the owners of web site A. Another issue is that the bandwidth that is paid by web site A's owners is being used by someone else. It would be a similar situation as a farmer's orchard getting raided for produce.How much of the internet's web pages are compliant with W3C standards?
According to the 2008 report from Opera only 4.3% of the internet abides by the W3C standards.What is googlewhacking?
Looking for two English words which when entered as a Google search, return exactly one page.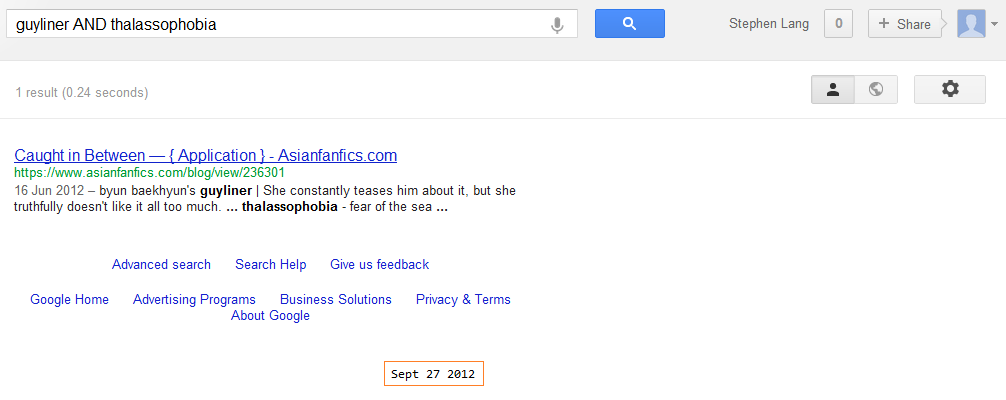
Back to Top
HTML
Why won't my HTML links work in the browser?
The browser may report an error if the link references are not defined properly. You will see a "Not found" possibly accompanied by a "404 HTTP Error" message appear in the browser. 1. In the browser click on View in the menu, then select the Source option. This brings up the HTML source for the current document. Locate the XHTML definition for the problem link and verify that the file name is correct and that file exists where the web server expects it to be (see absolute vs relative links). If the href attribute starts with something like "file:///C:/...", then your link will not work. What you have done is saved your XHTML with local links by mistake. The proper href attribute must either be a URL (like "http://www.camosun.ca/index.html") or a relative link (like "report.htm" or "../index.htm" or "reports/Sept_02.htm"). 2. Check that you have the file name correct in the anchor - case matters! If your XHTML is <a href="MyFile.htm">, then make sure that link file's name is "MyFile.htm" and not "myfile.htm". Also, in this example that file, MyFile.htm, should be in the same folder as the XHTML file that references it. 3. You may have to remove an older version of that XHTML file from the browser's cache. In Microsoft IE click on Tools in the menu and select Internet Options. Click on the "Delete Files" button on the Temporary Internet Files section. Click OK. Refresh the XHTML file in the browser. 4. If you are using named links, make sure you have the "#" in the reference. 5. Don't forget the </a> end tag and where it needs to go in the XHTML. You want to surround the text or image with the <a href="..."> and the </a> tags. 6. Make sure the permissions on the link file are correct. The link files must be readable to "other". The Unix command chmod go+r file will do the trick.What about frames?
Frames allow you to partition your browser window into separate regions--each region or "window" having its own HTML file. This is useful for setting up a frame that displays just navigation icons which will stay fixed as the main region or content window is scrolled. The trouble with frames is that using them can wreak havoc with your browser bookmarks. You don't want to bookmark the navigation window for example. Frames are currently discouraged in web construction for this reason. Read Jakob Nielsen's assessment of frames for more information. Another interesting article about frames.What does hypertext mean?
Hypertext means accessing the material in a nonlinear fashion. Novels are read in a linear order page by page. Magazines can usually be read in any order. Hypertext contains cross-references to other material, documents, even video and audio. This idea is used to a great advantage on the Internet as web pages can point their readers to other sources (links).What does hyperlink mean?
A hyperlink is a reference to another part of the current web page or another web page somewhere else on the Internet. The hyperlink or link is the foundation of the world wide web.Do I have to name my HTML files with a .htm or a .html?
Use the file extension html. Although htm will work (and it was required when using Windows 3.1), the better form is the extension html.What does it mean when we say HTML files are text files?
HTML files contain human-readable text. They are not binary files like an MS Word document. There are no hidden control characters used in HTML. You can easily read an HTML file using a simple text editor.What does "white-space" mean?
White space is the term for the extra spaces, tabs and new lines in your source document to enhance its readability.Will it make a difference in the browser if I add spaces and blank lines in my HTML file?
No. The browser will ignore any white space in the HTML source. This does not apply when defining the HTML tags; do not add white space after the < and > characters. For example, the tag < html> is not correct.What is an example of good HTML source code style?
Adopt a layout that will make the HTML as readable as possible to humans.<html> <head> <title>Welcome to my web page! </title> </head> <body> This is my first web page. My table: <table> <tr> <td>September</td> </tr> <tr> <td>October</td> </tr> </table> </body> </html>
What is an example of bad HTML source code style?
<html><head><title>Welcome to my web page!</title><body>This is my first web page My table:<table><tr><td>September</tr><tr><td>October</tr></table></body>
- no white space (unreadable)
- missing end tags (won't validate)
Are there other markup languages?
Yes. SGML is the father of markup languages and is still used. XML (eXtensible markup language) is used to define metadata structure. MathML (Mathematics markup language) for rendering mathematical equations. MML (Music markup language) for defining music score.What is XSLT?
Extensible stylesheet language transformation (XSLT) defines the format of how you want XML data to appear. It doesn't modify the existing XML file but creates a new one instead.What are HTML entities?
These are typographic characters and symbols you want the browser to show including non-English letters like ñ é ∀ Ω € † • ¼ , etc . For example, say you want to enter a less-than sign or greater-than sign in your HTML, if you type in a < or a > symbol in your HTML, the browser may be confused - are you missing part of an HTML tag? The way around that is to enter<for < and
>for >. The browser recognizes special symbols (entities) that start with an ampersand and end with a semicolon. Another HTML entity is
to force a space (the browser treats it like a space). The list of HTML entities is found at www.w3.org.
What is XHTML?
XHTML is stricter form of the HTML version 4.01. It was designed to clean up some of the "bad habits" of early HTML - such as inconsistent usage or missing tags. With XHTML, browsers can handle HTML code without having to fill in any missing parts.
XHTML documents have three parts: the DOCTYPE, the head and
the body. The DOCTYPE defines the document type like this:
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
XHTML tags must in lower case, they must balance correctly and they must have an end tag. A balanced set of HTML tags looks like this: <b><i>apple</i></b> -- the end tag for italics must appear before the end tag for bold. Any tag that wouldn't normally have an end tag in early HTML, such as <br> , <p> <hr>, and <img>, in XHTML needs to be modified like this: <br /> , </p> <hr />, and <img ...="" /> - an extra space before the / is required.
Other XHTML tag rules
- All tag attributes must in lower case like this <img src="tree.png" width="100" />
- All tag attribute values must be in quotes.
- Tag attributes cannot be minimized. The HTML tag <input checked > is not XHTML-compliant; the correct form in XHTML is <input checked="checked" />
- The name attribute is deprecated in favour of id. Use name only when you need to be compatible with older browsers (pre IE ver 6).
What is a shtml file?
With server side includes (SSI) you direct the web server to process some information within the HTML page before it is sent to
the browser. Usually this involves including the contents of one or more files into the HTML page. SSI must be enabled from the
web server end to support it.
SSI syntax is simple: <!--#directive parameter=value parameter=value -->. Some examples -
demo.shtml.
<!--#include file="data.txt"--> |
Inserts the file data.txt into the current HTML page. |
<!--#echo var="DATE_LOCAL"--> |
Show the current date. The format can be changed with the #config directive.
|
<!--#config timefmt="%A %B %d, %Y"--> |
Change the format of the current date to "Monday November 9, 2009" |
<!--#flastmod file="index.html"--> |
Show the modification date of the file index.html. |
Back to Top
Flash
How do I get motion tweening to work in Flash?
Check the Flash introduction tutorial.Can I use Flash MX at home?
Yes, you can but you must save the Flash movie as version 5 if you want to show it in the browser on the campus. Also, you may not be able to edit the Flash MX movie file from Flash 5.How do I get sound into my Flash movie?
Adding sound is easy. If you need to find some sounds other than the few supplied by the common library in Flash 5, you can find some web sites under my Support page which feature sound files you can save on your U: drive. Look for sound files that have the file extensions WAV, AIFF, or MP3. Once you download the sound files you want, you import them into Flash by clicking on File, Import and select the downloaded sound files. Importing the sound file doesn't make the sound part of the movie. You must add it to the movie's Timeline. You can add a new layer to your Flash movie (this will be a layer that handles all the necessary sound events or music). You should probably rename the layer appropriately to something like "Sound Effects" or "Sound Background". Insert a keyframe on the new sounds layer. Make sure the keyframe on the sounds layer is selected. On the Windows menu, select the Panels option, then select the Sound suboption. This will activate the Sound panel on the Flash desktop where you can select some sounds and any other sounds you imported into Flash. Just select the sound from the pulldown menu labelled Sound and your sound is copied into the keyframe.How do I get a button into my Flash movie?
Insert a new layer in your movie's timeline. This layer will handle one or more buttons you place into your movie. Make sure this layer is selected. From the menu select Window | Common Libraries and select Buttons. A new buttons dialog window should appear. Scroll down the list of buttons shown until you find the button style you want - maybe it is the "Pill Button" you want. Click on it to select it and the red pill button image will appear in the view portion of the window. Drag the pill button from the view portion onto your stage. Don't forget to turn on the Control | Enable Simple Buttons option.
How do I get my button to make a sound?
Right click on the button and select "Edit in Place" from the context menu that appears. A button's movie timeline will appear. Insert a new layer and rename it "sounds". Click on the frame that is on the sounds layer and is under the "Over" column. Press the F6 key. This means you want to insert a new sound when the mouse is over the button. Click on Window | Common Libraries | Sound to bring up some built-in sound effects. Drag any one sound effect onto the stage and you should see the sound profile appear in the keyframe. Return to the main movie timeline by clicking on the Scene 1 scene. You may have to adjust your workstation's speaker. Don't forget to turn on the Control | Enable Simple Buttons option.
How do I change how my button looks when I activate it?
Right click on the button and select "Edit in Place" from the context menu that appears. A button's movie timeline will appear. Select a keyframe and observe the button's appearance on the stage for that keyframe. You can modify the button for any keyframe to change the appearance for Up, Over, Down, Hit button events.How do I get my button to do something useful?
Right click on the button and select "Actions". From the Basic Actions double click on Play from the Add Action menu. This button will play the movie. Other Basic Actions include "Stop" to stop the movie, "Go To" to make the movie move to a specific frame in the movie, and "Get URL" to load up a new URL in the browser.How did you do that crazy Comp 140 Flash?
This was done with the masking feature and four layers. I created layer 1 which consisted of a rectangle that was filled with the rainbow colour. A second layer (layer 2) was added which was the mask layer consisting of the text "Comp 140" in the Jokerman font size 50 or so. I resized that rainbow rectangle so that the text would fit just inside of it. The colour of the text doesn't matter because it was the mask layer. Anything on the mask layer will be made transparent to the layer it masks. I moved layer 2 above layer 1, and make layer 2 masked. This makes the text appear filled in with the rainbow colours. Next I added a regular layer 3 above layer 2. Layer 3 was a copy of the text from layer 2 except that the colour of the text was a radial fill of yellow to orange. I added layer 4 next and moved it above layer 3. Layer 4 was a motion tween of a star object that spun clockwise once from left to right, then back to left again. I made layer 4 a mask and my Flash was done.Back to Top
DreamWeaver
What do you mean by local folder?
The local folder is the location where you perform development on your web site. This is the not the production folder. You need a safe area where you can test and complete updates to your web site separate from the production folder (the "remote folder"). For this reason, the local folder should never be the same as the production folder. If the local folder were defined to be the same as the production folder, then you would be putting your live web site at risk to any modifications you make. Generally you should define the local folder to be something like "InDev" or "Development" or "Comp140\DevSite" so that the purpose of this folder is obvious. You would not want the local folder to begin with "public_html" because that is the production area.What do you mean by remote folder?
The remote folder is the location of your live web site. This area contains all the tested HTML, JavaScript, Java, and image files and folders your web site needs. The remote folder will have to be defined starting with "public_html" if you are using the "local network" option to upload files.How do I set up my site?
Click on the Site | New Site menu option to create a new DreamWeaver site. You can provide the local root folder and HTTP Address settings similar to what is shown below: Then click on the
"Remote Info"
Category on the
left. You
have two choices for Access: FTP or local/network. Use FTP if
you want to
work from home but you do not have a U: connection to
Camosun. The FTP
option will automatically provide the access privileges to your web
files when
you upload them to the web site.
Then click on the
"Remote Info"
Category on the
left. You
have two choices for Access: FTP or local/network. Use FTP if
you want to
work from home but you do not have a U: connection to
Camosun. The FTP
option will automatically provide the access privileges to your web
files when
you upload them to the web site.
 If you select
the
local/network
option, then you will have to
provide the
remote folder as U:\public_html\...
Use this option
if you can connect to your Camosun U: drive from home. After
you upload
files to your web site, you will need to set the access privileges on
them so
that the browser can read them.
If you select
the
local/network
option, then you will have to
provide the
remote folder as U:\public_html\...
Use this option
if you can connect to your Camosun U: drive from home. After
you upload
files to your web site, you will need to set the access privileges on
them so
that the browser can read them.

How do I specify the FTP settings?
WARNING: FTP is a nonsecure protocol - use this only if you are unable to use SSH. If you are unable to establish a connection to your Camosun U: drive from home, you should be using the FTP remote info setting.| Host | deepblue.camosun.ca |
| Host directory | public_html or public_html\xxx where xxx is your subfolder |
| Login | your c0xxxxx number |
| Password | your c0xxxxx password |
Where is the imagemap panel?
When you select an image, the properties window should appear possibly near the bottom of the screen. If the complete window does not show up as below, then click on the small triangle on the lower right of the window.